알리바바 Tongyi DeepResearch : AI 연구의 '딥시크 모멘트'
왜 '파라미터 수'가 아니라 '훈련 방식'이 중요한지 증명한 오픈소스 AI 에이전트
요약
- Tongyi DeepResearch는 알리바바가 개발한 오픈소스 AI '연구 에이전트'로, 단순한 LLM이 아닌 복잡한 장기 연구 작업을 자율 수행하도록 설계되었습니다.
- 이 모델은 30.5B 파라미터 중 3.3B만 활성화하는 고효율 MoE 아키텍처를 채택하여, 적은 비용으로도 OpenAI의 o3 등 고비용 폐쇄형 모델을 벤치마크에서 능가합니다.
- 핵심 혁신은 '에이전트 훈련 파이프라인'으로, 비싼 인간 주석 없이 '자동화된 합성 데이터'를 생성하여 모델을 훈련시킵니다.
- 추론 시 'IterResearch'라는 독자적인 방식을 사용하여, 긴 컨텍스트의 한계를 극복하고 인간처럼 정보를 반복적으로 종합하며 보고서를 정제합니다.
- 이 모델의 오픈소스화는 고성능 AI 연구의 '민주화'를 촉발하며, 인간 전문가의 역할을 단순 자료 조사에서 전략적 판단 및 검증으로 변화시키고 있습니다.
오픈소스 에이전트 연구원의 시대 개막
알리바바 Tongyi Lab에서 개발한 Tongyi DeepResearch(통이 딥리서치) 모델은 단순한 대규모 언어 모델(LLM)이 아닙니다. 이것은 '장기 심층 정보 탐색(long-horizon, deep information-seeking)'이라는 명확한 목적을 가지고 특별히 설계된 고도로 자율적인 '에이전트(agentic) 모델'입니다. 개발팀의 명확한 목표는 AI가 인간의 지적 생산성을 증강시키고 잠재적으로 '해방(liberating)'시키는 것이며, Tongyi DeepResearch는 오픈소스 AI 연구원의 시대를 여는 기념비적인 작업입니다.
Tongyi DeepResearch의 가장 중대한 시장 및 기술적 의의는 '성능과 효율성의 비대칭성'을 성공적으로 구현했다는 점입니다. 이 모델은 총 305억 개(30.5B)의 파라미터 중 단 33억 개(3.3B)의 파라미터만 토큰당 활성화하는 희소 혼합 전문가(Mixture of Experts, MoE) 아키텍처를 채택했습니다.
이 경량화된 접근 방식은 엄청난 계산 효율성을 의미하며, 이는 AI의 확장성에 대한 기존의 통념에 도전합니다. 이 아키텍처를 통해, 670B에서 1T+ 파라미터에 이르는 경쟁사의 거대 모델들과 동등하거나 그 이상의 벤치마크 성능을 달성했습니다. 이는 AI의 지능과 성능이 순수하게 파라미터 수에 비례하지 않음을 증명하는 강력한 사례입니다.
그러나 Tongyi DeepResearch의 진정한 혁신은 모델의 파라미터 수가 아닙니다. 혁신의 핵심은 두 가지 핵심 소프트웨어 스택에 있습니다. 첫째는 '에이전트 훈련 파이프라인(Agentic Training Pipeline)'이며, 둘째는 'IterResearch'로 명명된 고유의 추론 패러다임입니다. 이 모델의 훈련 파이프라인은 훈련 프로세스와 환경 설계를 깊이 결합시키는 새로운 접근 방식을 취합니다. 이는 AI 에이전트 개발 경쟁의 패러다임이 '파라미터 스케일' 경쟁에서 '훈련 방법론 및 데이터 합성' 경쟁으로 이동하고 있음을 강력하게 시사합니다.
전략적 관점에서 볼 때, 이 고성능 모델의 완전한 오픈소스화는 중대한 시장 파괴적 사건입니다. 이는 OpenAI의 o3 Deep Research나 Perplexity의 Sonar Deep Research와 같이 고비용의 폐쇄형(closed-source) '딥 리서치' 서비스 시장에 대한 강력한 도전입니다. 이 모델은 AI 연구의 '대규모 민주화(Democratization of research at scale)'를 촉발하는, AI 에이전트 분야의 'DeepSeek 모멘트'로 평가될 수 있습니다. 본 보고서는 이 모델의 아키텍처, 훈련 방법론, 추론 방식, 성능 벤치마크, 그리고 시장에 미치는 함의를 기술적 관점에서 정밀하게 해부합니다.
Tongyi DeepResearch의 정의: '장기 심층 정보 탐색' 에이전트란 무엇인가
Tongyi DeepResearch의 개념을 명확히 하기 위해서는, 이것이 기존의 AI 시스템과 어떻게 근본적으로 구별되는지 이해해야 합니다. 이 모델은 알리바바가 이전에 진행했던 'WebAgent 프로젝트'의 경험과 기술을 계승하고 발전시킨 차세대 시스템입니다.
'딥 리서치'의 개념적 차별성
'딥 리서치' 에이전트는 기존의 검색 증강 생성(RAG)이나 대화형 챗봇과는 다른 차원의 작업을 수행하도록 설계되었습니다.
- 전통적 RAG (Retrieval-Augmented Generation)와의 비교: RAG 시스템은 본질적으로 정적(static)입니다. RAG 시스템은 사전에 구축된 벡터 데이터베이스에서 관련성 높은 정보를 '검색(retrieve)'하고, 이를 컨텍스트로 활용하여 답변을 '증강(augment)'하는 데 그칩니다. 즉, RAG는 이미 존재하는 지식의 '검색 보조' 도구입니다. 반면, Tongyi DeepResearch와 같은 딥 리서치 에이전트(DRA)는 동적(dynamic)인 라이브 웹 환경과 상호작용합니다. 이 모델은 단순한 검색을 넘어, 인간 연구원이 수행하는 연구 워크플로우 전체를 자율적으로 모방하고 실행합니다. 이 워크플로우는 '주제 정의', '작업 계획 수립(plan tasks)', '실시간 웹 브라우징(browse)', '소스 식별 및 열람(open sources)', '사실 추출 및 비교(extract and compare facts)', '인용을 포함한 노트 작성(keep notes with citations)', '최종 결과 종합(summarize results)'에 이르는 전 과정입니다.
- 일반 챗봇과의 비교: 일반적인 챗봇은 주로 단일 턴(turn)의 질의응답(Q&A)에 최적화되어 있습니다. 사용자의 즉각적인 질문에 빠른 답변을 제공하는 것이 목적입니다. 반면, Tongyi DeepResearch는 단일 질문에 즉시 답하는 것이 아닙니다. 이 모델은 '장기(long-horizon)' 및 '다단계 추론(multi-step reasoning)'을 요구하는 복잡하고 개방적인(open-ended) 연구 과제를 해결하도록 설계되었습니다. 이 시스템의 목표는 인간 연구원이 수 시간(several hours) 동안 수행해야 할 연구 작업을 수십 분(tens of minutes) 내로 단축하여 지적 생산성을 해방시키는 것입니다.
핵심 기능: 자율적 워크플로우 수행
기능적 관점에서 볼 때, Tongyi DeepResearch는 단순한 정보 생성을 넘어 '인지적 계획(cognitive planning)'과 '정보 융합(information fusion)'을 통합합니다. 이 에이전트는 다음과 같은 엔드-투-엔드(end-to-end) 워크플로우를 자율적으로 수행할 수 있는 시스템 수준의 역량을 갖추고 있습니다:
- 작업 인식 (Task Recognition): 사용자의 복잡한 연구 요구사항을 이해합니다.
- 다단계 분해 (Multi-stage Decomposition): 복잡한 목표를 달성 가능한 하위 작업들로 분해하고 체계적인 계획을 수립합니다.
- 이기종 검색 (Heterogeneous Retrieval): 웹 페이지, PDF 문서, 학술 논문, 심지어 로컬 파일 등 다양한 형태의 소스에서 정보를 검색합니다.
- 교차 소스 집계 (Cross-source Aggregation): 여러 소스에서 수집된 정보를 비교, 대조, 교차 검증(cross-validate)하여 신뢰성을 높이고 정보 간의 모순을 식별합니다.
- 구조화된 보고서 생성 (Structured Report Generation): 모든 탐색과 분석을 종합하여, 출처가 명확히 인용된 체계적인 보고서를 생성합니다.
기반 모델 및 MoE의 전략적 활용
Tongyi DeepResearch의 놀라운 성능은 그 기반이 되는 하드웨어 효율적인 아키텍처에서 시작됩니다. 이 모델은 알리바바의 최신 Qwen 모델 시리즈 중 하나인 Qwen3-30B-A3B-Base 모델을 기반으로 초기화되었습니다. 이름에서 알 수 있듯이, 이는 혼합 전문가(MoE) 아키텍처를 채택하고 있습니다
- 파라미터 상세: 모델의 총 파라미터 수는 305억 개(30.5B)입니다. 하지만 추론 시 모든 파라미터가 사용되는 것이 아닙니다. 토큰당 약 33억 개(3.3B)의 파라미터만이 선별적으로 활성화됩니다.
- 희소 활성화 (Sparse Activation): 이는 토큰당 전체 파라미터의 약 10.8%($3.3 \div 30.5$)만이 계산에 참여함을 의미합니다. 이 '희소 활성화' 전략은 MoE 아키텍처의 핵심 이점을 극대화합니다. 즉, 30.5B급 대형 모델의 방대한 지식 용량(capacity)과 복잡성을 보유하면서도, 실제 추론에 필요한 계산 비용(compute cost)은 3B급 소형 모델 수준으로 획기적으로 낮춥니다.
성능의 비대칭성 분석
Tongyi DeepResearch의 등장은 AI 시장의 지배적인 패러다임에 중요한 질문을 제기합니다. AI 모델의 지능이 순수하게 파라미터 수에 비례하는가라는 질문입니다.
최근 AI 시장은 DeepSeek v3.1 (671B) 또는 Kimi (1T)와 같이 파라미터 수를 기하급수적으로 늘리는 '스케일업(Scale-up)' 경쟁에 몰두해왔습니다. 하지만 Tongyi DeepResearch는 '스마트업(Smart-up)' 전략을 선택했습니다. 단 3.3B의 활성 파라미터로 최첨단(SOTA) 성능을 달성한 것은, 모델의 지능이 파라미터 수에만 의존하는 것이 아님을 보여줍니다. 오히려 '특화된 훈련(specialized training)'과 '효율적인 아키텍처'가 훨씬 더 중요할 수 있음을 입증하는 강력한 사례입니다.
이러한 아키텍처적 효율성은 '더 저렴하고 빠른' 추론을 가능하게 합니다. 이는 OpenAI의 o3 Deep Research와 같이 토큰당 높은 비용이 부과되는 폐쇄형 상용 API가 장악한 시장에서, 고성능 오픈소스 모델의 상업적 배포를 재정적으로 실현 가능하게 만드는 핵심 동력입니다. 실제로 일부 API 중개 서비스에서는 이 모델을 무료 또는 극히 저렴한 비용으로 제공하고 있습니다.
핵심 철학: 환경 결합 훈련
Tongyi DeepResearch의 SOTA 성능은 MoE 아키텍처만으로는 설명될 수 없습니다. 그 비밀의 핵심은 모델을 '연구원'으로 탈바꿈시킨 고도로 정교한 '에이전트 훈련 파이프라인'에 있습니다.
Tongyi DeepResearch의 훈련 파이프라인은 기존 LLM 훈련 방식과 근본적인 철학적 차이를 보입니다. 개발팀은 "환경을 수동적인 외부 현실로 보지 않고, 훈련 프로세스와 깊게 결합된 능동적으로 설계된 시스템으로 재정의"했습니다. 이는 에이전트가 단순히 정적인 데이터를 '읽는' 것이 아닙니다. 시뮬레이션된 웹 환경, 코드 실행기, 파일 파서 등과 '상호작용하며 학습'함(Learning Through Environmental Interaction)을 의미합니다.
데이터 기반: 완전 자동화된 합성 데이터 파이프라인
이러한 환경 결합 훈련을 가능하게 하는 것은 '완전 자동화된 합성 데이터 생성 파이프라인'입니다.
이 파이프라인의 중요성은 아무리 강조해도 지나치지 않습니다. 이는 '비용이 많이 드는 인간의 주석(costly human annotation)' 과정 없이, 훈련에 필요한 모든 단계(사전 훈련, 지도 미세 조정(SFT), 강화 학습(RL))의 데이터를 완전 자동으로 생성합니다. 이는 AI 개발의 가장 큰 병목이었던 고품질 데이터 확보 비용을 기하급수적으로 낮춥니다.
더 나아가, 이 파이프라인은 데이터의 '최신성(freshness)'을 보장하며, 모델을 지속적으로 개선할 수 있는 사실상의 '무한 동력'을 제공합니다. 이는 수개월 또는 수년 전의 정적 데이터셋(예: Common Crawl)에 의존하는 기존 모델 훈련 방식의 근본적인 한계를 극복한 것입니다. AI 에이전트 시대에 '데이터 합성 능력'은 반도체 시대의 '무어의 법칙'과 같이, 모델의 성능을 좌우하는 새로운 핵심 지표가 되고 있습니다.
엔드-투-엔드(End-to-End) 훈련 레시피
Tongyi DeepResearch의 훈련은 '에이전트 중간 훈련(Agentic Mid-Training)'과 '에이전트 사후 훈련(Agentic Post-Training)'을 통합하는 독특한 엔드-투-엔드 프레임워크를 따릅니다.
1단계: Agentic Mid-Training (AgentFounder 활용)
- 목적: 이 단계는 전통적인 일반 사전 훈련(pre-training)과 에이전트 특화 사후 훈련(post-training) 사이의 거대한 간극을 메우는 '가교' 역할을 합니다. 모델에 처음부터 '에이전트적 편향(agentic biases)', 즉 계획하고, 도구를 사용하고, 추론하는 경향성을 주입하는 것이 목표입니다.
- 방법 (AgentFounder): 'AgentFounder'라는 시스템이 이 역할을 수행합니다. AgentFounder는 단순한 행동(예: 단순 계획, 추론)의 데이터와 복잡한 다중 결정 행동의 데이터를 포함하는 대규모의 고품질 '에이전트 궤적(agentic trajectories)' 데이터를 자동으로 생성합니다. 모델은 이 데이터를 바탕으로 '지속적인 사전 훈련(continual pre-training)'을 받습니다. 이 훈련은 32K 컨텍스트(1단계)와 128K 컨텍스트(2단계)로 나누어 진행됩니다.
2단계: Agentic Post-Training (SFT) (WebSailor-V2 & WebShaper 활용)
- 목적: 지도 미세 조정(Supervised Fine-Tuning, SFT)을 통해 모델의 특정 에이전트 능력을 더욱 날카롭게 다듬습니다.
- 방법 (WebSailor-V2 & WebShaper): SFT 단계에서도 합성 데이터가 핵심적인 역할을 합니다.
- WebSailor-V2: '순환 그래프(정보가 서로 연결된 구조)'를 생성하고 '무작위 보행(데이터를 무작위로 탐색하는)' 기법을 사용하여, 정보 간의 상호 연결성을 높인 고품질 QA(질의응답) 지식 그래프 데이터셋을 생성합니다.
- WebShaper: '계층적으로 정보를 확장해나가는 탐색' 전략을 사용하여 생성된 데이터의 품질을 더욱 향상시킵니다.
- 이 데이터는 SFT 단계의 '콜드 스타트(cold start, 초기 학습)'에 사용되어 모델이 RL 단계로 넘어가기 전에 강력한 기반을 갖추도록 합니다.
3단계: End-to-End Reinforcement Learning (RL) (GRPO 활용)
- 목적: 실제와 유사하게 설계된 환경과의 상호작용을 통해 모델의 행동 정책(policy)을 최적화하고, 장기 작업 수행 시 안정성을 확보합니다.
- 방법 (GRPO): Tongyi DeepResearch는 표준적인 PPO 대신, 'GRPO(Group Relative Policy Optimization)'라는 강화 학습 알고리즘을 채택했습니다. GRPO는 기존 방식(PPO)의 다소 불안정한 평가 모델을, 보다 안정적인 '그룹 점수'로 대체합니다.
- 이 훈련은 API 호출 비용 없이 시뮬레이션된 웹 환경에서 엄격한 '온-폴리시(on-policy, 학습 중인 정책을 바로 실행하는)' 접근 방식을 따릅니다.
- 특히 환경이 계속 변하는 비정상(non-stationary) 환경에서 훈련을 안정화시키기 위해 더 정교한 학습을 위한 고급 강화 학습 기법들이 총동원되었습니다. 예를 들어, 학습에 방해가 되는 불필요한 데이터를 걸러내는 필터링은 모델이 긴 훈련 중에 의미 없는 결과물로 붕괴되는 것을 방지하는 데 필수적입니다.
두 가지 작동 패러다임 - ReAct vs. IterResearch
Tongyi DeepResearch의 혁신은 훈련 단계에서 그치지 않습니다. 추론(inference) 시, 즉 사용자가 모델을 실제로 사용할 때, 두 가지 매우 다른 작동 패러다임을 지원합니다. 이는 작업의 복잡성에 따라 경비행기와 점보제트기를 선택하는 것과 같습니다.
패러다임 1: ReAct (표준 모드)
- 정의: 'ReAct'는 2023년 ICLR 학회에서 제안된 표준적인 에이전트 프레임워크로, 'Reason(생각) - Act(행동) - Observe(관찰)'의 사이클을 반복합니다. 에이전트는 먼저 '무엇을 할지' 생각하고(Reason), 도구를 사용해 '행동'하며(Act), 그 결과를 '관찰'하여(Observe) 다음 생각을 이어갑니다.
- 용도: 이 모드는 모델의 '핵심 내재적 능력(core intrinsic abilities)'을 프롬프트 엔지니어링과 같은 외부적 도움 없이 엄격하게 평가하기 위해 사용됩니다.
패러다임 2: IterResearch ('Heavy' 모드)
- 목적: 'IterResearch'는 ReAct의 한계를 극복하고 모델의 '최대 성능 잠재력(maximum performance ceiling)'을 발휘하기 위해 Tongyi Lab이 독자적으로 개발한 '테스트 시점 스케일링 전략(test-time scaling strategy)'입니다. 이 모드는 특히 복잡하고 여러 단계로 구성된 연구 작업을 위해 설계되었습니다.
- 핵심 문제 인식: ReAct와 같은 기존의 '단일 컨텍스트(mono-contextual)' 접근 방식은 장기 연구 작업에서 치명적인 약점을 보입니다. 연구가 진행될수록 모든 검색 결과, 생각, 관찰이 단 하나의 컨텍스트 창에 선형적으로 축적됩니다. 이는 결국 컨텍스트 창의 용량을 초과하여 중요한 초기 정보를 잃어버리거나, 관련 없는 정보가 과도하게 쌓여 추론의 질을 떨어뜨리는 '컨텍스트 질식(context suffocation)'과 '노이즈 오염(noise contamination)'을 유발합니다.
- 솔루션 (IterResearch): IterResearch는 이 문제를 알고리즘적으로 해결합니다.
- 연구 과정을 재정의: 딥 리서치 작업을 '마르코프 결정 과정(Markov Decision Process, MDP)'이라는 단계별 의사결정 문제로 재정의합니다. 이 방식은 주기적으로 작업 상태를 새롭게 구성합니다.
- 반복적 합성 워크플로우: 선형적 누적이 아닌 '반복적 합성(iterative synthesis)'을 수행합니다. 에이전트는 각 연구 '라운드(round)'마다, 이전 라운드의 모든 기록을 버리고 오직 '가장 본질적인 결과물(essential outputs)'만을 가져와 새로운 작업 공간(workspace)을 재구성합니다. 이 깨끗한 작업 공간에서 '중앙 보고서(central report)'를 점진적으로 발전시키고 다음 행동을 결정합니다. 이 반복적인 '합성 및 재구성' 프로세스는 에이전트가 긴 작업 내내 명확한 '인지적 초점'과 높은 추론 품질을 유지하도록 합니다. 또한 이 패러다임은 노이즈 방지 및 품질 검사 기능도 포함합니다.
- 훈련 효율성: 이 접근 방식은 훈련 시에도 이점을 가집니다. 긴 궤적(trajectory) 하나가 단 하나의 훈련 샘플이 되는 대신, 각 '라운드'가 개별적인 훈련 샘플(상태, 응답, 도구 응답)이 되어 훈련 데이터의 양과 질을 모두 높입니다.
- 'Heavy' 모드로의 확장: 이 IterResearch 패러다임을 기반으로 'Research-Synthesis' 프레임워크가 제안됩니다. 이 'Heavy' 모드에서는 여러 연구 에이전트(Research Agents)가 병렬로 문제를 탐색하고, 최종 종합 에이전트(Synthesis Agent)가 이들의 보고서를 통합하여 더 포괄적인 답을 생성합니다. 이는 신뢰성을 높이기 위한 프리미엄 계층으로 사용될 수 있습니다.
IterResearch 패러다임의 등장은 '워크플로우가 컨텍스트를 이긴다'는 중요한 시사점을 던집니다. Tongyi DeepResearch는 128K라는 명백한 컨텍스트 창의 한계를 가지고 있습니다. 이는 Gemini 1.5 Pro의 2M 토큰이나 Claude 2의 200K에 비하면 부족해 보입니다. 하지만 Tongyi는 단순히 컨텍스트 창을 물리적으로 늘리는 대신, '지능적인 망각'과 '주기적인 종합'이라는 인간의 실제 연구 방식을 모방한 알고리즘적 워크플로우를 통해 컨텍스트를 '보유'하는 것이 아닙니다. 컨텍스트를 '효율적으로 관리'하는 것이 더 중요할 수 있음을 보여주었습니다.
성능 및 벤치마크 정밀 분석
Tongyi DeepResearch는 주요 에이전트 검색 벤치마크에서 최첨단(SOTA) 성능을 달성하며 그 기술력을 입증했습니다. 이 모델의 핵심 역량 중 하나는 단일 정보원에 의존하지 않고, 다중 소스에서 얻은 정보를 '교차 검증(cross-validate)'하고 '종합(synthesize)'하는 능력입니다.
에이전트는 여러 조사 라운드를 수행하며 이해도를 점진적으로 심화시키고, 정보 간의 모순을 해결하며, 새로운 연구 방향을 탐색합니다. 이는 초기 발견이 새로운 질문을 제기하거나, 소스 간 정보가 상충(conflicting)하는 복잡한 실제 연구 환경에서 필수적입니다.
다음 표는 주요 딥 리서치 벤치마크에서 Tongyi DeepResearch와 주요 폐쇄형 상용 모델들의 성능을 비교 분석한 것입니다.
[주요 딥 리서치 에이전트 벤치마크 성능 비교]
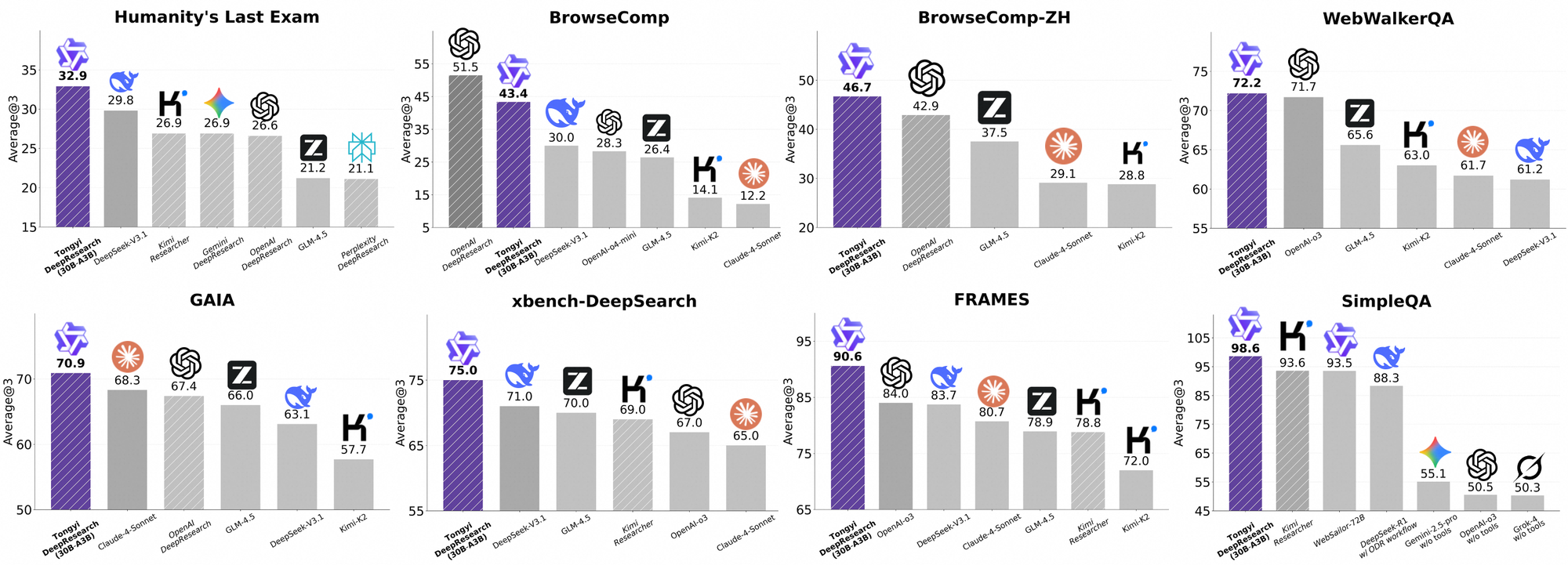
| 벤치마크 (Benchmark) | Tongyi DeepResearch (30.5B-A3.3B) | OpenAI o3 Deep Research | Gemini 2.5 Pro Deep Research | Grok 4 DeepSearch | Perplexity Sonar Deep Research |
| Humanity's Last Exam (HLE) | 32.9% | 24.9% | 37.6% | 34.5% | 21.0% |
| GAIA (범용 에이전트) | 70.9% | N/A | N/A | N/A | N/A |
| BrowseComp (EN) | 43.4% | N/A | N/A | N/A | N/A |
| BrowseComp (ZH) | 46.7% | N/A | N/A | N/A | N/A |
| xbench-DeepSearch | 75.0% | 67.0% | N/A | N/A | N/A |
| FinDeepResearch (금융) | 30.3% | N/A | 36.6% | 34.5% | 23.0% |
N/A: 해당 벤치마크에 대한 공개된 점수 없음.
이 벤치마크 데이터는 몇 가지 매우 중요한 전략적 시사점을 제공합니다.
- 오픈소스의 승리 (HLE, xbench): Humanity's Last Exam(HLE)은 웹에서 찾기 힘든 정보를 끈질기게 탐색하고 추론해야 하는 초고난도 벤치마크입니다. 이 벤치마크에서 Tongyi DeepResearch(32.9%)는 OpenAI o3(24.9%)와 Perplexity Sonar(21.0%)를 압도적인 차이로 능가했습니다. xbench-DeepSearch에서도 마찬가지로 o3(67.0%)를 상대로 75.0%라는 높은 점수를 기록했습니다. 이는 고도로 특화된 에이전트 훈련을 받은 오픈소스 모델이, 범용으로 개발된 거대 폐쇄형 상용 모델을 복잡한 웹 탐색 작업에서 이길 수 있음을 보여주는 충격적인 결과입니다.
- 안정적인 범용 에이전트 성능 (GAIA): GAIA(범용 자율 지능 에이전트) 벤치마크에서 70.9%라는 높은 점수는 이 모델이 단지 검색만 잘하는 것이 아닙니다. 복잡한 다단계 작업을 계획하고 안정적으로 수행할 수 있는 견고한 범용 에이전트임을 증명합니다.
- 명확한 한계 (FinDeepResearch 및 BrowseComp): 반면, 최근 공개된 금융 분석 전문 벤치마크인 FinDeepResearch에서는 다른 양상이 나타납니다. 이 벤치마크에서 Tongyi(30.3%)는 가장 최신의 강력한 폐쇄형 모델인 Gemini 2.5 Pro(36.6%)와 Grok 4(34.5%)에 뒤처지는 성능을 보였습니다. 이는 Tongyi가 범용 딥 리서치에서는 매우 뛰어나지만, 금융과 같이 고도로 전문화된 도메인의 초고난도 분석 작업에서는 여전히 최신 상용 모델들과 격차가 존재함을 시사합니다. 또한, 일부 분석가들은 Tongyi가 BrowseComp 벤치마크에서 상대적으로 부진한 이유가 128K라는 컨텍스트 길이의 한계 때문일 수 있다고 지적합니다.
전략적 경쟁 구도 분석: 오픈소스 vs. 폐쇄형 거대 기업
Tongyi DeepResearch의 등장은 딥 리서치 시장의 경쟁 구도를 근본적으로 재편하고 있습니다.
vs. OpenAI o3 Deep Research
Tongyi는 HLE 벤치마크에서 o3를 성능으로 능가했을 뿐만 아니라, 시장의 핵심 변수인 '비용' 측면에서 파괴적인 영향력을 행사합니다. OpenAI o3 Deep Research는 200K 컨텍스트를 제공하지만, 입력 토큰당 $10/M, 출력 토큰당 $40/M라는 매우 높은 비용이 책정되어 있으며, 웹 검색 도구 사용 시 추가 비용까지 발생합니다.
반면, Tongyi DeepResearch는 완전한 오픈소스로 공개되었습니다. 이로 인해 로컬 배포 시 비용이 거의 없거나, OpenRouter와 같은 API 중개 서비스를 이용하더라도 o3에 비해 극히 저렴한 비용 (심지어 무료)으로 이용할 수 있습니다. 이는 '고급 연구'의 높은 비용 장벽을 무너뜨리는 결정적인 사건입니다.
vs. Perplexity Sonar Deep Research
Perplexity의 Sonar Deep Research는 200K의 긴 컨텍스트를 바탕으로 다단계 검색, 종합, 보고서 생성을 수행하는 강력한 상용 에이전트입니다. 이 모델 역시 재무, 기술, 건강 등 복잡한 영역에서 포괄적인 보고서 생성을 목표로 합니다. 그러나 HLE 및 FinDeepResearch 벤치마크 결과에서 볼 수 있듯이, 현재 공개된 성능 수치상으로는 Tongyi DeepResearch에 비해 열세를 보이고 있습니다.
vs. 학술/전문 도구 (Elicit, Scopus AI)
시장에서 종종 혼동되는 Elicit이나 Scopus AI와 같은 도구들과의 비교는, Tongyi DeepResearch의 정체성을 더욱 명확하게 합니다.
이는 'RAG 보조원'과 '자율적 연구원'의 근본적인 차이입니다. Elicit이나 Scopus AI와 같은 도구들은 기본적으로 학술 데이터베이스라는 폐쇄된 코퍼스 내에서 '문헌 검토(literature review)'를 보조하는 고도화된 RAG 도구에 가깝습니다. 이 도구들은 기존 검색보다 정밀도(precision)는 높을 수 있지만, 연구에 필요한 모든 문헌을 찾는 민감도(sensitivity)는 부족하다는 한계가 명확히 보고된 바 있습니다. 실제로 한 연구에 따르면, Elicit은 체계적 문헌 검토에서 민감도가 평균 39.5%에 불과하여, 전통적인 문헌 검색을 대체할 수 없다는 결론을 내렸습니다. 이 도구들은 보조적인(adjunct) 용도로는 유용합니다.
반면, Tongyi DeepResearch는 '웹 에이전트(Web Agent)'입니다. 이 모델은 학술 자료에 국한되지 않고 동적인 웹 전체를 탐색하며, 필요에 따라 코드를 실행하고 로컬 파일을 분석(File Parser)하는 등, 인간의 개입을 최소화하는 '엔드-투-엔드(end-to-end)' 자율 워크플로우를 수행합니다. 즉, Elicit이 인간의 연구를 '보조(assist)'하는 도구라면, Tongyi DeepResearch는 연구를 '수행(conduct)'하는 에이전트에 가깝습니다.
주요 적용 분야 및 고가치 활용 사례
Tongyi DeepResearch의 진정한 가치는 벤치마크 점수가 아닌, 복잡한 실제 세계의 고가치 문제에 적용될 때 드러납니다.
금융 및 시장 인텔리전스 (Finance & Market Intelligence)
이 분야는 딥 리서치 에이전트의 가장 즉각적이고 파급력 있는 적용처입니다.
- 기업 연구 코파일럿: 조직 내에서 '경쟁사 분석(competitive analysis)', '공급업체 실사(vendor due diligence)', '시장 진입 타당성(market entry feasibility)' 보고서를 자율적으로 생성할 수 있습니다. 이는 내부 '리서치 데스크' 역할을 수행하며 인트라넷과 웹 소스 전반에 걸쳐 감사 가능한(auditable) 장문의 보고서를 생성합니다.
- 구체적 고가치 활용: EmergentMind의 분석에 따르면, Tongyi DeepResearch는 다음과 같은 매우 구체적인 금융 작업에 투입될 수 있습니다:
- 실적 발표 종합 (Earnings call synthesis): 여러 분기의 실적 발표 성적서(transcripts)와 재무제표를 분석하여 핵심 KPI와 경영진의 톤을 요약합니다.
- 경쟁사 제품 티어다운 (Competitor product teardowns): 경쟁사의 신제품 관련 뉴스, 리뷰, 기술 문서를 수집하여 제품의 강점과 약점을 분석합니다.
- 시장 규모 분석 (TAM/SAM analysis): 다양한 시장 보고서와 데이터를 종합하여 목표 시장의 규모를 추정합니다.
- M&A 루머 검증 (M&A rumor verification): 웹상의 상충되는 루머와 신호(contradictory signals)를 교차 검증하여 신뢰도를 평가합니다.
- 특화 워크플로우: 이러한 작업을 위해 Tongyi DeepResearch는 'Search/Visit'와 같은 웹 도구뿐만 아니라, 재무제표나 성적서(filings, transcripts)를 읽기 위한 '파일 파서(File Parser)', 핵심 KPI 계산을 위한 'Python' 실행기를 사용합니다. 특히 '상충되는 신호'를 분석해야 하는 고난도 작업에는 'Heavy Mode'(즉, IterResearch 패러다임)가 사용됩니다.
법률, 정책 및 규제 분석 (Legal, Policy & Regulatory Analysis)
법률 및 정책 분야는 정보의 정확성과 출처의 명확성이 극도로 중요한 영역입니다.
- 활용: '정책 분석(policy analysis)', '기술 평가(technology evaluation)', '규제 감시(regulatory watch)' 등에 사용됩니다. 이는 법안, 규칙 제정, 기관 지침, 표준 업데이트 등을 추적하고 내부 이해관계자를 위한 영향 및 필요 조치 요약 보고서를 생성하는 작업을 포함합니다.
- 핵심 가치: 법률 및 정책 문서는 수많은 '교차 참조(cross-references)'로 복잡하게 얽혀있습니다. 한 조항의 변경이 다른 수십 개의 문서에 영향을 미칠 수 있습니다. 모든 정보를 단일 컨텍스트에 누적하는 ReAct 방식으로는 이러한 복잡성을 추적하기 어렵습니다. 반면, Tongyi의 IterResearch 패러다임은 각 라운드마다 보고서를 정제하며 복잡한 참조 관계를 체계적으로 추적하고 종합 보고서를 생성하는 데 최적화되어 있습니다.
학술 연구 및 기술 평가 (Academic Research & Technology Evaluation)
'학술 연구(academic research)' 및 '증거 종합 보조(evidence synthesis assistant)'는 이 모델의 또 다른 핵심 적용 분야입니다. 특히 수백 편의 논문을 검토해야 하는 '체계적 문헌 검토(systematic review)' 프로세스를 자동화하여 연구 속도를 획기적으로 높일 수 있습니다. 이는 범위 검토(scoping reviews), 논문 분류(paper triage) 등을 반자동화하고, 'Scholar' 및 'File Parser' 도구를 활용해 PDF를 가져오고 분석하며, 'Python'을 사용해 간단한 메타 분석까지 수행할 수 있습니다.
비판적 평가: 명확한 한계와 공식 로드맵
Tongyi DeepResearch가 이룬 혁신적인 성과에도 불구하고, 이 모델은 명확한 기술적 한계를 가지고 있으며, 개발팀 역시 이를 인지하고 있습니다.
기술적 한계 (1): 128K 컨텍스트 창의 병목 현상
- 문제: 모델의 최대 컨텍스트 길이는 128K 토큰입니다. 이는 GPT-4-turbo(128K)와 동일하지만, Claude 2(200K)나 Gemini 1.5 Pro(2M)와 같은 최신 경쟁 모델에 비해 우위가 없거나 부족합니다.
- 저자들의 인정: 논문 저자들은 이 128K 컨텍스트가 "가장 복잡한 장기 작업을 처리하기에 여전히 불충분하다(remain insufficient)"고 기술 보고서에서 명시적으로 인정했습니다. 또한 BrowseComp 데이터셋에서 상대적으로 뒤처지는 성능 역시 이 컨텍스트 한계 때문일 수 있다고 분석됩니다.
- 분석: 앞서 언급했듯이, IterResearch 패러다임은 이 한계를 알고리즘적으로 '완화(mitigate)'하지만 '제거(eliminate)'하지는 못합니다. 책 한 권 분량의 전체 텍스트를 한 번에 분석하는 등의 초장기 작업을 위해서는 물리적인 컨텍스트 확장이 필수적으로 요구됩니다.
기술적 한계 (2): 모델 규모 및 보고서 품질
- 모델 규모: 현재 시장에 출시된 것은 30.5B 모델이 유일합니다. 개발팀은 "더 큰 규모의 모델(larger-scale model)"이 '현재 진행 중(currently in progress)'이라고 밝혔습니다. 이는 현재 모델이 경량급(3.3B) 활성 파라미터로 달성할 수 있는 성능의 최대치에 가까울 수 있음을 시사합니다.
- 보고서 품질: 저자들은 '보고서 생성 충실도(report generation fidelity)'와 '사용자 선호도에 정렬된(preference-aligned outputs)' 결과물을 '지속적으로 개선 중'이라고 언급했습니다. 이는 현재 생성되는 보고서가 인간 전문가가 즉시 사용할 수 있는 최종 결과물(final deliverable) 수준이라기보다는, 검토와 수정이 필요한 정교한 '초안(draft)' 수준일 수 있음을 시사합니다.
공식 로드맵: 향후 개발 방향
Tongyi Lab은 이러한 한계를 극복하기 위한 명확한 로드맵을 제시하고 있습니다.
- 컨텍스트 확장: 128K를 넘어선 '초장기 컨텍스트(ultra-long horizons)' 지원. 이는 책 한 권 분량의 분석과 같은 작업을 목표로 합니다.
- 모델 확장: 현재 '진행 중'인 '더 큰 MoE 기반' 모델의 검증 및 출시. 이는 확장성(scalability)의 한계를 탐색하기 위함입니다.
- 강화 학습(RL) 개선: 훈련 효율성을 높이기 위한 '부분 롤아웃(학습 범위를 나누어 효율을 높이는)' 및 비정상 환경에 대응하기 위한 '오프-폴리시(학습 중인 정책과 다른 정책을 따르는)' 방법 탐색.
- 기능 확장: 커뮤니티 기여를 통해 '비전(vision)' 또는 '다국어(multi-lingual)' 도구를 통합하여 모델의 적용 범위를 확장합니다.
결론: AI 연구의 '민주화'와 인간 전문가의 역할 진화
Tongyi DeepResearch의 등장은 AI 연구 및 개발 생태계에 두 가지 심오한 변화를 예고합니다.
첫째, 이는 AI 연구의 '민주화(Democratization)'를 가속화하는 'DeepSeek 모멘트'입니다. 지금까지 OpenAI, Google 등 소수의 거대 테크 기업들이 주도하던 고성능 딥 리서치 영역은 높은 비용과 기술 장벽으로 인해 접근이 제한적이었습니다. Tongyi DeepResearch는 이러한 고성능 에이전트 모델과 그 훈련 파이프라인 전체를 오픈소스로 공개함으로써, 전 세계의 개발자, 스타트업, 중소기업이 고비용의 상용 API에 의존하지 않고도 강력한 딥 리서치 기능을 구축하고 활용할 수 있는 길을 열었습니다. 자원이 부족한 조직이라도 이제는 '경쟁사 분석', '시장 진입 타당성'과 같은 복잡한 분석의 기초 작업 70~80%를 달성할 수 있게 되었습니다.
둘째, 이는 '인간 전문가의 역할 재정의(Evolving roles of consultants and researchers)'를 강제합니다. Tongyi와 같은 자율 에이전트가 '경쟁사 분석', '시장 진입 타당성'과 같은 복잡한 분석 작업의 70~80%를 자동화할 수 있게 됨에 따라, 인간 전문가의 역할은 근본적으로 변할 수밖에 없습니다.
- 인과 관계: 인간 연구원과 컨설턴트는 더 이상 '초기 데스크 리서치(initial desk research)'와 같은 반복적이고 시간 소모적인 저부가가치 업무에 매몰되지 않습니다.
- 새로운 역할: 이들은 AI가 제공할 수 없는 '가치 사슬의 더 높은 단계(further up the value chain)'로 이동해야 합니다. 이들의 새로운 핵심 역량은 AI가 생성한 방대한 초안의 '신뢰성(factual grounding)'과 '편향성(bias risks)'을 검증하고 (이는 여전히 중대한 우려 사항입니다), 이를 바탕으로 전략적인 '판단(judgment calls)', '시나리오 계획(scenario planning)', 그리고 데이터만으로는 알 수 없는 '문화적/구현적 통찰(cultural/implementation insights)'을 제공하는 것입니다.
최종적으로, Tongyi DeepResearch는 단순히 더 효율적이거나 강력한 LLM이 아닙니다. 이는 AI가 인간의 지적 생산성을 '대체'하는 것이 아니라 '해방(liberating)'시키는 새로운 패러다임의 시작을 알리는 신호탄입니다. 이는 AI 에이전트가 생성한 정교한 '초안'을 바탕으로, 인간 전문가가 더 높은 수준의 '전략적 통찰'을 더하는, 새로운 차원의 협업 시대를 여는 핵심 기술입니다.


Comments ()